There is a quiet war raging inside modern enterprises, and it isn’t between your IT department and overseas hackers. It is between your Information Security (InfoSec) team and your own employees.
Consider a scenario playing out in corporate offices globally:
An organization deploys an aggressive new authentication policy on its corporate environment. To “maximize” security, the system demands re-authentication multiple times a day.
It doesn’t care if a user is actively typing – it abruptly forces a re-login
in the middle of a sentence, wiping out unsaved form data.
You say – this surely doesn’t happen?
Yet, I’ve seen it. In real life.
Eventually, a high-performing employee simply stops using the system.
When a client asks, “Why aren’t you logging into the platform?” the worker provides an honest, devastating response:
“The security tools are so disruptive to production that it is impossible to do any work in them. If your system fails to recognize an active, ongoing session, that isn’t security—it’s a productivity tax and a fundamental design flaw.
Fix it.”
When a company’s strongest security controls actively throttle revenue generation, the security posture has failed.
Security should be a locked door, not a treadmill employees must sprint on while trying to type.
As a seasoned tech chief who has sat in both the business-growth and risk-management seats, I view this tension through a very pragmatic lens. True protection does not come from draconian restriction – It comes from:
Smart Security.
An approach built on economic deterrence, user enablement, and turning your workforce from perceived vulnerabilities into your most agile defense asset.
1. The Core Philosophy: Attacker Economics
Many security professionals treat corporate defense as a binary: You are either 100% secure or you are completely exposed, only that – this mindset is an executive failure. True security is an economic (and to some degree, a political) optimization problem.
The foundation of Smart Security rests on a simple formula: maximize the cost to the attacker until it exceeds the potential value of the targeted asset.
Cost of attack > Value of the asset.
Smart security aims to make your organisation less profitable, less predictable, and less scalable to attack than the alternatives.
In simple plaintext;
If a cybercriminal targets corporate data worth €10,000 on the dark web, your job is not to build a billion-euro fortress.
Your job is to architect a defensive barrier that costs the attacker €10,001 in resources, computing power, or time to breach.
The moment the math doesn’t track, the rational, financially motivated adversary moves on to an easier target – nobody in their sane minds spends €100 to get a return of €99.
The Nation-State Exception
There is, of course, a critical caveat to this economic rule – If your organization is targeted by a politically or ideologically motivated adversary, such as a state-sponsored Advanced Persistent Threat (APT) group, the ROI model breaks down as these actors possess virtually unlimited budgets and no requirement for financial return.
If a nation-state actor is fully committed to breaching your network, they will likely find a way in,
practically no matter what.
In these rare, high-stakes environments, trying to prevent initial entry by torturing employees with constant MFA prompts is like using a cardboard shield against a railgun – Instead, the strategy must pivot from absolute prevention to resilience and blast-radius containment.
You design the architecture under the assumption of breach, ensuring the adversary cannot move laterally or cause catastrophic, existential damage. Make your staff your allies and educate on the how, why and when’s, and make it rewarding!
2. Security Friction Breeds “Shadow IT”
When an InfoSec team implements oppressive security controls, they do not actually increase the cost to the attacker – they merely increase the cost to the employee.
This is the classic mistake of confusing friction with security.
When you force an employee to navigate hostile user design, they do not stop needing to meet deadlines – Instead, they find workarounds. They copy-paste sensitive corporate data into unmanaged local text files to avoid losing work, they migrate projects to personal Dropbox folders or unsanctioned generative AI tools.
This is the birth of Shadow IT.
Traditional CISOs routinely blame the workforce for being reckless when these workarounds occur, but a strategic leader looks at Shadow IT and recognizes it as a structural security failure, not a personnel failure.
High friction forces good employees to make bad security decisions just to cope and do their jobs.
Smart Security focuses on reducing friction so that compliance automatically becomes the path of least resistance.
3. From the “Department of No” to Business Enablers
To eliminate Shadow IT and align the organization, InfoSec must undergo a cultural evolution. The legacy approach to security was bureaucratic and binary: Is this new software or workflow 100% risk-free? No? Then block it at the firewall.
A modern, strategic InfoSec function operates as a business enabler. Its default posture must shift from a flat “No” to a collaborative “Yes, and here is how we do it safely.”
| Legacy “Department of No” |
The Smart Security Enabler |
| “You cannot use this external generative AI tool. It is completely blocked.” |
We see how this AI tool triples your output. Let’s route it through our private API wrapper so company data doesn’t leak into public training models.” |
This shift does not mean InfoSec abdicates its governing duty or becomes a rubber stamp.
As executive leaders, the buck stops with us and InfoSec retains the absolute right, and the explicit duty to veto an initiative if the residual risk inherently exceeds the possible gains or violates the organization’s risk appetite.
They are the ultimate gatekeepers, and rightly so.
However, because a Smart Security team rarely issues a flat rejection, their veto carries immense corporate weight.
When they finally do say “No,” the business units do not push back or seek a workaround – they comply immediately because a solid foundation of trust and understanding of why, has been built.
The C-suite and the board will always back a CISO or InfoSec team that says, “We engineered three different architectural workarounds to make this project happen, but the inherent risk remains unacceptable.”
4. Turning the Workforce into “Trusted Sensors”
The ultimate goal of Smart Security is to build a high-functioning ecosystem that leverages distributed intelligence. By pairing the technical expertise of the security team with the operational context of the workforce, you create a powerful symbiosis.
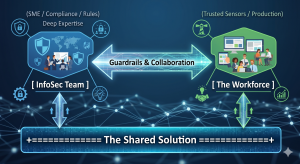
InfoSec understands the threat landscape, regulations (ISO, NIST, SOC2, …), and system vulnerabilities. The users understand how the business actually functions, what clients require, and where the operational bottlenecks sit. When these two forces work in conjunction, they discover viable solutions that satisfy compliance while maintaining production velocity.
Crucially, this model transforms employees into trusted sensors and early detectors.
No automated Endpoint Detection and Response (EDR) software or AI-driven email filter is flawless.
The ultimate line of defense against sophisticated social engineering or a targeted Business Email Compromise (BEC) is a human who notices that something is “off.”
If an employee feels valued and supported by InfoSec, they will instantly flag a suspicious event, but if they operate in a culture of fear, resentment, or high friction, they will stay silent, or blindly click through authentication prompts just to clear their screens.
5. Gamifying the Culture: The InfoSec Challenger
How do you bring this philosophy to life?
You take security awareness out of the realm of boring, punitive, check-the-box compliance compliance training and turn it into a transparent, gamified corporate sport.
Instead of deploying trick phishing simulations designed to catch employees out and sentence them to mandatory training videos, flip the paradigm entirely – Challenge the workforce to catch the InfoSec team out.
By launching a monthly “IT InfoSec Challenger of the Month” initiative, you incentivize proactive vigilance through friendly competition:
-
The Scope: Staff members earn points and recognition for providing valuable security insights, flagging emerging industry threat vectors, identifying an operational vulnerability, or spotting a live configuration error in an internal corporate application, acting as a collaborative and willing extension to the InfoSec team.
-
The Rewards: The prizes do not need to be massive corporate cash payouts. In organizational psychology, status and micro-rewards drive higher engagement. A bottle of bubbly, a digital badge on the companywide corporate newsletter, a small desk trophy, or a dinner voucher for two with their plus-one creates highly coveted bragging rights and a personal reward with recognition that stays with them.
This framework creates a no-lose scenario for the enterprise. If staff members successfully catch a blind spot or process vulnerability, InfoSec wins because they can patch the flaw before a malicious actor exploits it.
If the staff fails to find a vulnerability but stays actively engaged trying to do so, InfoSec still wins because the baseline vigilance of the entire company skyrockets.
When a member of the accounting or operations team wins the award, security ceases to be an abstract corporate policy – It becomes a badge of honor celebrated among peers.
The Bottom Line
 Power board design…
Power board design…

 Verse 2
Verse 2









 I could not have said this any better myself, as to why there is a silent shift happening.
I could not have said this any better myself, as to why there is a silent shift happening.